
Microsoft Professional Program for Big Data: my journey (Oct 2017 - Apr 2019)
by Patrick Lee on 22 May 2019 in categories actuarial BigData with tags Azure Data Factory Azure Data Lake dashboard lifelong learning Microsoft R Server NoSQL PowerBI Python SQLAzure T-SQL USQLI was very pleased to complete this program (a series of 10 courses) in April 2019, working in my spare time. The Microsoft Academy page for this program is currently here.
Overview
The program involved taking 10 courses which were:
- Microsoft Professional Orientation: Big Data (completed in October 2017)
- Analyse and Visualize Data (completed on the Data Science program in July 2017)
- Work with NoSQL Data (August 2018)
- Query Relational Data (completed on the Data Science program in June 2017)
- Implement a Data Warehouse (September 2018)
- Process Big Data At Rest (December 2018)
- Process Big Data In Motion (February 2019)
- Orchestrate Big Data Workflows (February 2019)
- Build Big Data Analysis Solutions (completed on the Data Science program in March 2018)
- Big Data Capstone Project (April 2019)
For several of the courses, alternative options were available (e.g. between Azure Data Lake Analytics and Hadoop for course 6, and between Azure Stream Analytics and Azure HDInsight for course 7). I chose the first option in each case to get to know the pure Microsoft technology because I felt that this would be more consistent and integrate more easily with the other Microsoft tools in their Azure cloud offering.
Note that although I started the program in October 2017 I didn't complete it until April 2019. That was because during May 2017 to April 2018 I was concentrating on completing Microsoft's Professional Program for Data Science (for my Data Science journey please see here). As noted above there was some overlap: three courses from the latter were also part of the Big Data program.
It took me 234 hours of part-time study to complete the Big Data program, 146 hours excluding the 3 courses that I had already completed as part of the Data Science program. My average mark across the 10 courses was 97.7%. (See here for some tips about how to achieve high marks in edX and other online courses).
Caution: for some of the labs (online exercises) the cloud computing resources can be quite expensive (£10 or significantly more if you leave the resources idle for several days, as compared to $99 for each course), so I often waited until the end of the course before doing the labs (and then deleted the relevant cloud resources as soon as I had finished the labs).
What is Big Data?
Precise definitions vary, but for this course "Big Data" was defined as a form of data with either a high volume (more than a million or two of records), or a large variety of formats (e.g. images, videos), or which comes very quickly (with high velocity).
During the course we explored the management and analysis of several different types of big data, including:
- structured data (with a fixed schema - a fixed list of fields - and fixed relationships between different tables or sets of data)
- unstructured data (with a variable schema - a variable list of fields - or where the data could be very general, e.g. tweets or blog posts or other documents)
- data at rest, where new records are added at regular intervals, e.g. once a day or once a week
- data in motion, where new records are added at very frequent intervals, e.g. in real time like stock market prices, or streaming data from Internet of Things ( IoT) devices.
The final course was a capstone project which involved three separate challenges that tested my ability to build Big Data solutions for:
- processing data at rest
- processing data in motion, and
- orchestrating a Big Data solution.
I try to give a brief idea below of what was involved in each course in the program. Note: like many other online courses, the material is updated from time to time, so may have changed if you take the course at a later date.
Course 1: Big Data Orientation
This covered
- an introduction to data, data formats and data files, storing files in Azure (Azure Storage and Azure Data Lake Store)
- an introduction to relational databases including data warehouses
- in introduction to NoSQL databases (key-value, document and graph databases). SQL stands for Structured Query Language, and NoSQL can either stand for "No SQL" or "Not only SQL" and is useful for unstructured or semi-structured data such as blog posts or tweets
- an introduction to big data processing (what is big data, data at rest, data in motion, batch and real-time processing in Azure, batch and real-time processing in HDInsight)
Course 2: Analysing and Visualising Data with Power BI
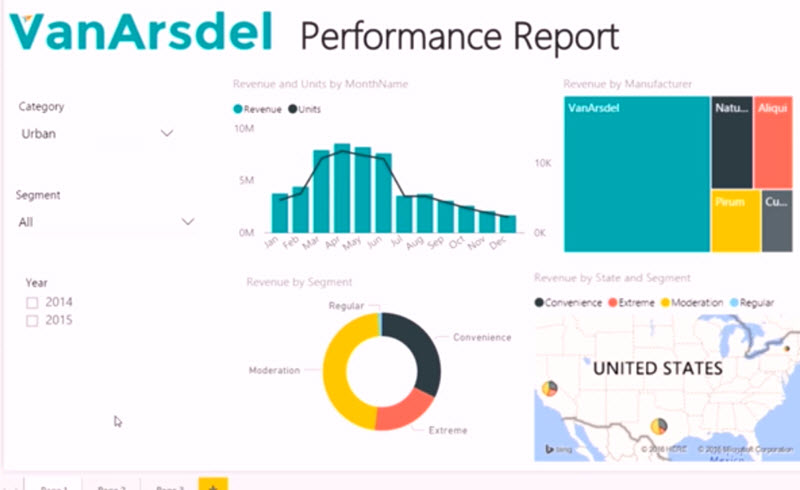
I completed this as part of the Data Science program. This showed how to produce visuals (and perform some analysis) in Microsoft Power BI (Business Intelligence).

Microsoft Power BI (like other programs e.g. Tableau) is very useful for producing interactive dashboards for senior management and others to extract insights from data. You can click on one chart to highlight a particular feature or filter the data, and all the other charts or tables adjust accordingly.
Course 3: Work with NoSQL Data
NoSQL also known as "not only SQL" is often used for unstructured data (or at least data that is less structured than relational data, and for which the fields can vary for different types of records within the same table).
This covered an introduction to:
- Key-Value stores, Azure storage tables
- Azure Cosmos DB
- MongoDB
- More NOSQL database solutions (including Cassandra, Lucene & Solr, Azure search, HBase and Redis)
Course 4: Querying with Transact-SQL
This was my second course from the Data Science Program and was also one of the courses on the Big Data Program. This taught how to query relational data to extract meaningful information.
This screenshot shows one way of extracting related data from two different tables:

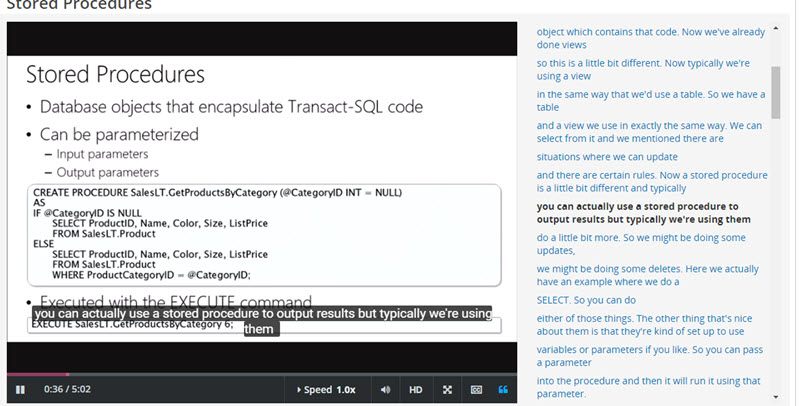
This screenshot shows part of the course describing Stored Procedures (bits of code that run on the database server, which is often more efficient than extracting the relevant data and doing the processing on a different server, e.g. a web server):
Course 5: Delivering a Data Warehouse in the Cloud
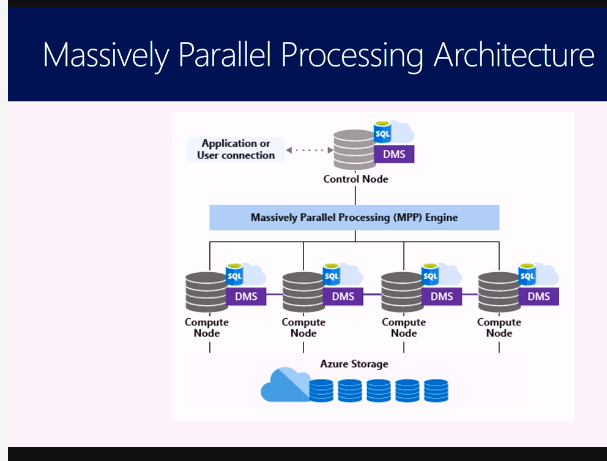
My 5th course was Delivering a Data Warehouse in the Cloud. This gave an introduction to SQL Data Warehouses, a specialised type of relational database where MPP (Massively Parallel Processing) can be used to query large volumes (hundreds of millions of records or more) of key data, which has usually been extracted from even larger volumes of raw data stored elsewhere.
Topics covered included:
- Designing and querying data warehouses (distributed tables, replicated tables, partitioned tables, indices and statistics, monitoring queries)
- Integrating data (loading data from raw data sources, including via Azure Data Factory, Azure Stream Analytics and Polybase).
- Analyzing data with Azure Machine Learning, visualizing data with Power BI, and integrating with Amazon Athena and Redshift
- Managing data warehouses (including columnstore fundamentals, SQL data warehouse security, managing computations including analyzing workloads, and backups).
This screenshot shows the architecture of Azure SQL Data Warehouse, with Massively Parallel Processing:
Course 6: Process Big Data at Rest (with Azure Data Lake Analytics)
Course 6: Process Big Data at Rest (with Azure Data Lake Analytics). Topics covered included:
- an overview of Azure Data Lake, an introduction to U-SQL, U-SQL fundamentals (U-SQL is a language that allows you to combine SQL with C#)
- Using a U-SQL Catalog
- using C# functions in U-SQL
- monitoring and optimizing U-SQL jobs
Course 7: Process Big Data in Motion
My 7th course was Process Big Data in Motion, Processing Real-Time Data Streams in Azure. This gave an overview of how to process large volumes of streaming data, e.g. from IoT (Internet of Things) devices in real time. Topics covered included:
- ingesting real-time data with Azure Event Hubs
- Ingesting real-time data with Azure IoT Hubs
- Analysing real-time data using Azure Stream Analytics
- Working with Temporal Windows
Course 8: Orchestrating Big Data Solutions
Parallel or distributed processing is often required when doing big data extraction, transformation and analysis. Some means of orchestrating the different tasks (including checking that they have all run successfully, rerunning those that failed, alerting the user if reruns have been unsuccessful, doing the various steps in the right order, combining the output from different tasks etc) is needed. This course covered how to use Microsoft's solution to this problem, Azure Data Factory.
Topics covered included:
- Introduction to Azure Data Factory
- Pipelines
- Scheduling Pipelines
- Transformations
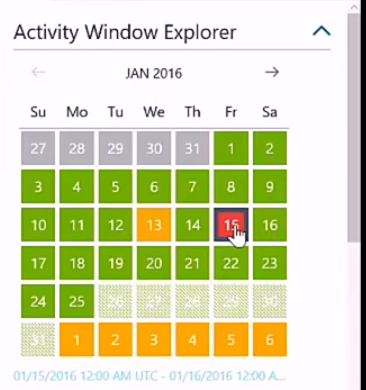
This screenshot shows Azure Data Factory's activity window explorer, which shows tasks that have completed successfully in green, those for which there is no data yet in grey, and those for which there is data but which haven't yet started in orange:
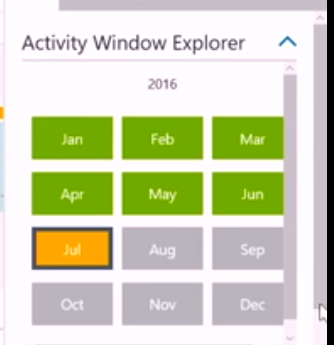
Processes which have run but failed are shown in red, as in this screenshot:
Course 9: Analyzing Big Data with R
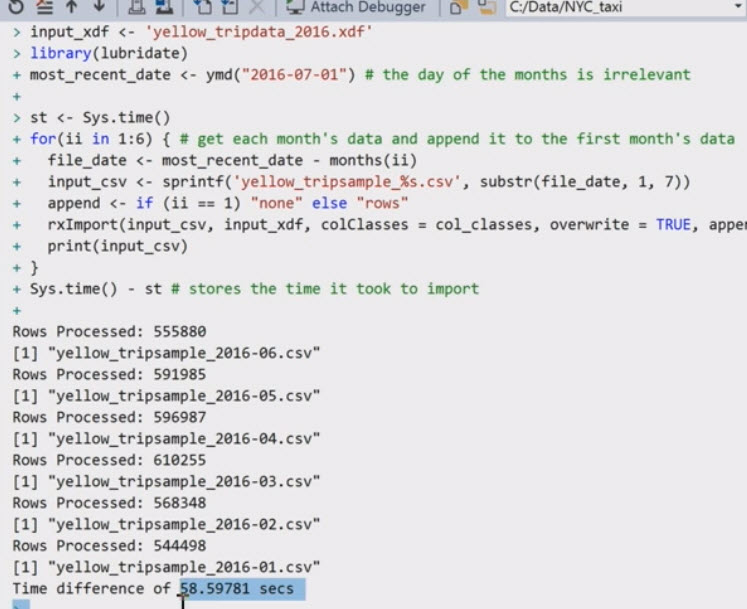
My 9th course (which I completed previously as part of the Microsoft Professional Program for Data Science) was Analyzing Big Data with Microsoft R Server. Standard R is limited to the memory of the computer running it. This showed how to use Microsoft R server for larger datasets.
Screenshot showing an example of some R server code:
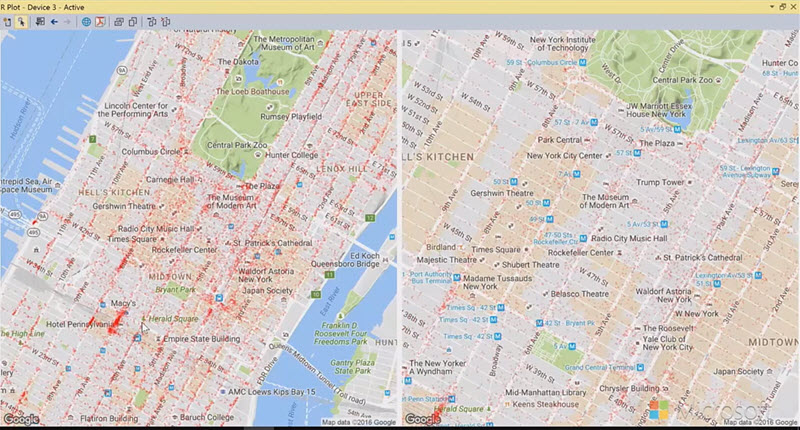
A screenshot showing some analysis of New York taxi data:
Course 10: Capstone Big Data
The 10th and final course (completed in April 2019) was a capstone project (one designed to bring several earlier courses together) with three separate challenges that tested my ability to build Big Data solutions for:
- processing data at rest
- processing data in motion, and
- orchestrating Big Data solutions.
Challenge one: processing big data at rest
This involved analysing data from about 16,000 text files, representing weekly stock inventory data during a full year for a large retail organisation with many stores. I had to extract the data, process it and send the processed data for each week to a data warehouse. Challenge one involved working on a particular week's data.
Challenge two: processing big data in motion
This involved receiving real-time stock adjustments from a simulated chain of retail stores, aggregating it over non overlapping one-minute intervals and analysing the results.
Challenge three: orchestrating a Big Data solution
This involved processing the weekly inventory data from challenge one by using Azure Data Factory to load data for each store and each week for a full year into a data warehouse and then analysing the output.
Conclusions
Storing and analysing big data (data of either large volume - e.g. more than a couple of million records, variety or velocity) requires quite different techniques from those normally used for smaller data sets. NoSQL databases can be very useful to handle unstructured data, or situations where the data schema may change in future. Different techniques are needed for handling real-time (streaming) data as compared to data at rest. In many big data situations, parallel or distributed processing is needed, together with some means (e.g. Azure Data Factory) to orchestrate (i.e. manage and combine) the different processes.
I found this professional program a very useful complement to the Data Science program (which covered predictive modelling itself, rather than how to use the very different techniques required to process big data).